오늘의 목표
- Pandas 패키지의 DataFrame 객체를 활용하여 데이터에 대한 탐색적 분석을 수행한다.
- DataFrame객체에서 조건에 의한 데이터 추출을 한다.
데이터 분석하기
1. 주피터 노트북에서 실습을 중단하고 다시 시작하는 분들은 [Cell-Run All] 선택
왜? 더 이상 메모리에 존재하지 않는 내용을 다시 읽어 들여 다음 작업이 가능해지도록 하기 위함

데이터를 바꿨습니다. 이걸로 다운받아서 사용하세요.
이 데이터들은 저번 시간처럼 C:\Users\컴퓨터사용자이름\Python\data에 넣어주세요.
2. describe() 함수
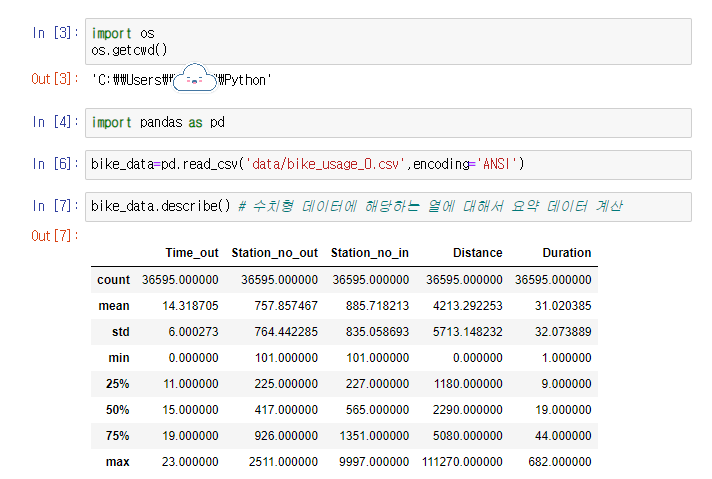
변수이름.describe(): 기본적인 통계 값을 한 번에 알아보는 방법, 데이터 중 수치형 데이터에 해당하는 열에 대해서 요약 데이터를 계산한다, 파이썬의 기본 함수가 아니라서 pandas를 import하지 않으면 사용할 수 없다.
count: 데이터의 개수
mean: 평균
std: 표준편차
min: 최솟값
25%: 1사분위수
50% 중앙값
75%: 3 사분위수
max: 최댓값
※사분위수: 데이터의 대부분이 어디에 분포하며 그 구간이 넓은지, 좁은지 쉽게 파악할 수 있어서 데이터 특성을 이해하는데 편리하다.
※평균, 중앙값: 데이터 전체를 대표하는 숫자를 찾는 것
※분산, 표준편차: 평균을 중심으로 데이터가 얼마나 흩어져 있는지 알려줌
3. describe함수를 보고 데이터 상세분석
■mean값
보아하니 Station_no_out(대여소 번호)와 같은 컬럼은 mean으로 검토할 대상은 아니다. 딱히 분석할 필요가 없다(대여소 번호의 평균을 굳이...). 대신, Distance(거리)나 Duration(기간)에 집중하여 분석을 진행해보자.
평균을 보면 Distance는 약 4213미터, Duration은 약 31분이다.
이 말은 즉슨 '사람의 걸음이 1시간에 4킬로미터 이동하는데, 자전거로 이용하면 평균 30분에 4킬로미터 이동한다'는 사실에 부합하여 이 데이터는 믿을만하다고 판단 내릴 수 있다.
■max값
distance: 대략 111270미터(=111킬로미터) / duration: 대략 682분(=11시간)
111270미터를 킬로미터로 바꾸면 111킬로미터에 11시간이 넘는 값이다.
자전거를 타고 최대 11시간 동안 111킬로미터를 갈 수 있을까?
[잠깐! DataFrame 이해하고 넘어가기]

bike_data의 타입을 확인해보면 결과창에 'pandas.core.frame.DataFrame'이라고 나와있다.
read_csv함수를 사용하여 데이터 파일을 읽으면 DataFrame타입의 구조가 된다.
그래서 우리가 따로 bike_data의 변수의 타입을 지정하지 않아도 DataFrame이라는 구조의 타입을 그대로 수용하게 된다.
pandas는 엑셀 같은 테이블 구조를 가진 DataFrame 타입을 사용한다. 그래서 데이터 분석에 편리한 다양한 기능을 제공한다. 변수를 하나 만들어 DataFrame타입에 데이터를 담으면 변수는 DataFrame의 다양한 기능을 상속한다.
상속받는다는 건 DataFrame 타입이 사용할 수 있는 기능을 자동으로 사용할 수 있다는 의미와 같다.
[잠깐! 변수의 '기능(메서드)' 사용법]
변수 이름.기능의 이름(내용)
끝의 괄호는 함수와 같은 성격인데, 특정 데이터 타입에 연결되어 있는 함수를 메서드라고 부른다.
[잠깐! 변수의 '속성정보' 사용법]
변수이름.기능의이름.내용
끝에 괄호가 사용되지 않는 것은 Attribute라고 하는 속성 정보에 해당한다.
4. columns 속성정보
변수이름.columns: 데이터의 칼럼 이름을 순서대로 보여준다.

5. head() 메서드
변수이름.head(숫자): 데이터의 x 줄의 정보를 보여준다.
만약, hean(5)라면 첫 5줄의 정보를, head(10)이라면 첫 10줄의 정보를 보여준다.

※ 인덱스: 결과창에 맨 왼쪽에 0,1,2,3,4라고 나와있는데 이걸 인덱스라고 한다. 인덱스는 항상 0부터 시작
6. tail() 메서드
변수이름.tail(숫자): 데이터의 마지막 x 줄의 정보를 보여준다.

7. shape 속성정보
변수이름.shape: 데이터의 행과 열의 크기를 알려준다.

8. info() 메서드
변수이름.info(): 데이터에 대한 전반적인 정보를 보여주는 메서드

36595 entries: 36595개의 행
15 columns: 15개의 컬럼
dtypes: 수치형 데이터(int64)가 5개, 수치형이 아닌 데이터 컬럼(object)이 10개
non-null: null이 아닌 데이터 개수를 표현해준다. (Gender컬럼은 다른 컬럼과 다르게 null값이 존재한다)
9. 그 외 주요 메서드
- count(): NA 값을 제외한 값의 수를 반환
- describe(): 각 열에 대한 요약 통계
- min(): 최솟값
- max(): 최댓값
- sum(): 합계
- mean(): 평균
- var(): 분산
- std(): 표준편차
- skew(): 왜도(치우침 정도)
- kurt():척도(뾰족함 정도)
- cumsum(): 누적 합
10. sum() 메서드
수치형 데이터가 아닌 10개의 컬럼까지 모두 합계한 결과가 보인다.

그럼 필요한 컬럼만 선택하여 평균을 내는 방법은?
11. 특정 컬럼의 값 추출하기
■방법1) 점을 찍고 해당 컬럼 이름을 명시하기
변수이름.컬럼이름: 해당 컬럼의 데이터를 앞, 뒤 5줄씩 보여줌


■ 방법2) 대괄호를 사용하기
변수이름['컬럼이름']: 해당 컬럼의 데이터를 앞, 뒤 5줄씩 보여줌
※대괄호를 사용하여 컬럼이름을 표시할 경우 따옴표를 사용해야 한다.


12. 특정 컬럼에서 고윳값 확인
변수이름['컬럼이름'].unique(): 특정 컬럼에서 고윳값 보여줌
데이터가 무엇으로 구성되어 있는지
※고윳값: 예를 들어 특정컬럼이름이 '과일'인데 이 과일컬럼의 데이터 값들이 '바나나', '사과', '배' 3개의 고윳값으로 이루어져 있다.

object타입의 정기권, 일일권, 단체권, 비회원으로 이루어져 있다.
13. 특정 컬럼의 고윳값의 각 개수 확인
변수이름['컬럼이름'].value_counts(): 특정 컬럼의 고윳값들의 각 개수를 알려줌

각 고윳값별로 몇 건의 데이터가 있는지 보여준다.
14. 특정 컬럼의 고윳값의 비율 확인
변수이름['컬럼이름'].value_counts(normalize=True): 특정 컬럼의 고윳값듣의 차지 비율

15. 수치형으로 인식되지 않는 컬럼 확인하기

Momentum(운동량): 수치형이어야 하는데 object
carbon_amount(탄소배출량): 수치형이어야 하는데 object
이 데이터들이 수치형으로 인식되지 않았는데 어떤 이유에서 그렇게 되었는지 확인해보자.

우선 Momentum컬럼에서 혹시 null값이 있는지 확인하기 위해 isnull.sum()을 확인해본다. 결과가 0이다.
그럼 null값이 없다는 의민데 왜 object가 나왔을까?
그럼 최솟값이 얼마인지 계산한다. min()함수와 max()함수를 써서 최소, 최댓값을 계산해본다.
최솟값은 0인데 최댓값이 알 수 없는 이상한 문자가 나온다.
\\N: ANSI타입으로 읽어 들이면서 빈칸으로 표시될 윈도우 형식의 표식을 문자로 해석하고 읽어 들여 전체 컬럼이 문자로 인식됨
그럼 '\\N'이 몇 개나 있는지 확인해보자.
16. 특정한 컬럼에 특정한 값을 가진 행 추출
변수이름[변수이름.특정컬럼명=='특정값']: 특정한 컬럼에서 특정값을 가진 행을 추출
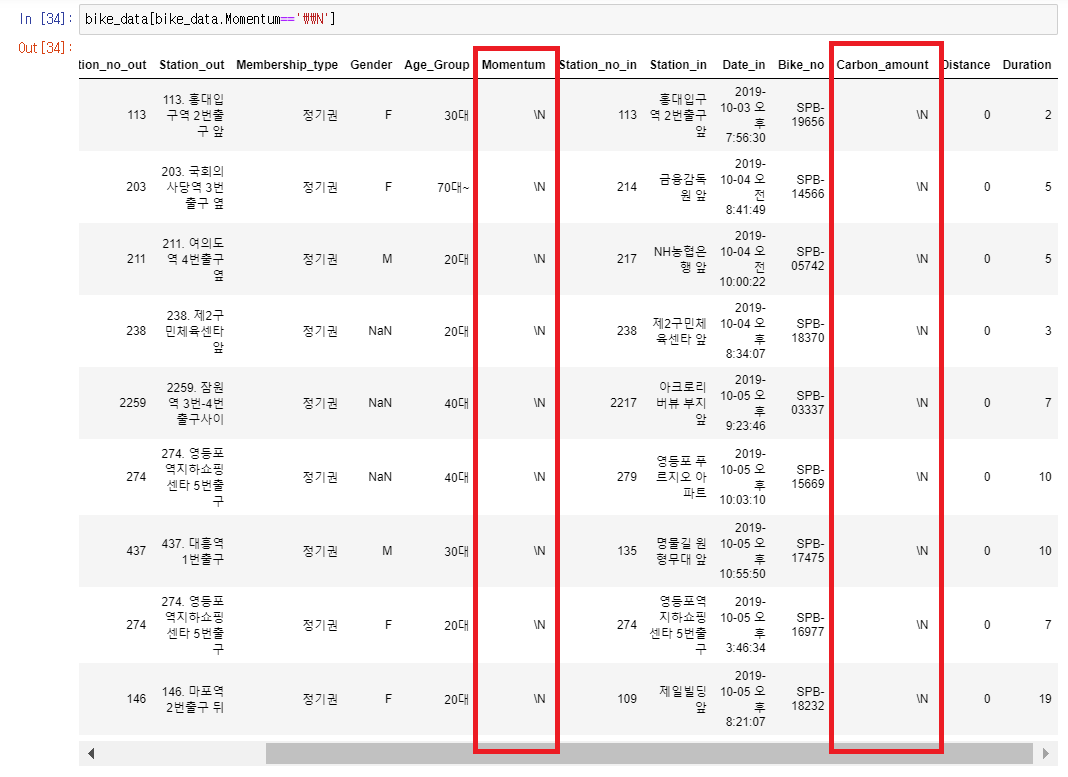
빈 값이나 적절하지 않은 데이터가 있어도 괜찮을까? 글쎄요. 괜찮을 수도 아닐 수도 있어요.
다음 REVIEW
결측 값, 이상 값 처리에 대해 알아보자.
'IT지식 > 파이썬으로 데이터분석' 카테고리의 다른 글
| [파이썬으로 데이터 분석하기3] 데이터 파일 업로드 방법, 그 외 문제 해결 (0) | 2021.11.27 |
|---|---|
| [파이썬으로 데이터 분석하기2] 주피터노트북 기초 세팅과 기초사용 (0) | 2021.11.23 |
| [파이썬으로 데이터 분석하기1] 아나콘다설치 방법, 주피터 노트북 실행방법 (0) | 2021.11.23 |
| jupyter notebook에서 csv파일 업로드 시 오류 (0) | 2021.10.13 |



